1.目的
配置环境,使能在Windows系统中使用Spark,并能够使用Python语言编程。
2.平台环境
Windows 10(1709)
Java 1.8.0(151)
Python 3.4.4
Hadoop 2.7.5
Spark 2.2.0
3.安装
3.1.Java
1) 下载
从http://www.oracle.com/technetwork/java/javase/downloads/
jdk8-downloads-2133151.html下载Java8,并且建议不要使用Java9,因为并不能够很好的兼容9,包括Cassandra,在使用的过程中会出现一些问题。安装的过程就一路Next就行了。
2) 环境变量
事实上,在安装的时候会添加Java的环境变量(如图2-1蓝色中的部分),但是这并足够,还需要新建变量JAVA_HOME、CLASSPATH,尤其是CLASSPATH。
a) JAVA_HOME:C:\Program Files\Java\jdk1.8.0_151
b) CLASSPATH:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
c) Path:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
关于Path的添加,如果界面如图2-1,则将其分成“%JAVA_HOME%\bin”和“%JAVA_HOME%\jre\bin”两部分;如果如图2-2,则直接复制“%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;”添加进去即可(以上部分的值均不包括引号)。
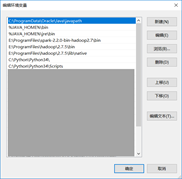
(a)
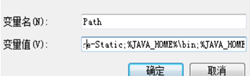
(b)
图2-1
正确配置完环境变量后,就能够响应java、javac等命令。
3.2.Python
1) 下载
从https://www.python.org/downloads/下载Python的安装包,目前的最高版本为3.6.5(截止至2018-04-26),这里使用的是3.4的版本。安装时注意不要使用带有空格的路径,如“C:\Program Files”等,也最好不要使用中文路径,避免出现什么问题。
2) 环境变量
如果装完Python环境变量中仍然不存在Python的路径,则如图2-1(a)中的最后两行所示,将“C:\Python\Python34\”与“C:\Python\Python34\Scripts”添加到环境变量中。
正确配置完环境变量,能够响应python命令。
3.3.Hadoop 2.7.5
1) 下载
2) 环境变量
新建环境变量HADOOP_HOME,值:E:\ProgramFiles\hadoop\2.7.5,并将E:\ProgramFiles\hadoop\2.7.5\bin(或者%HADOOP_HOME%\bin)放到Path中去。
3) 配置
以下所说的路径均是基于Hadoop 的根目录E:\ProgramFiles\hadoop\2.7.5
a) 在Hadoop 的根目录下,新建workplace目录,并在workplace中新建子文件夹temp、data、name,在E:\ProgramFiles\hadoop下新建文件夹E:\ProgramFiles\hadoop\workplace\2.7.5\data
b) 编辑etc\hadoop\core-site.xml
1 | `<configuration> <property> <name>hadoop.tmp.dir</name> <value>/E:/ProgramFiles/hadoop/2.7.5/workplace/temp</value> </property> <property> <name>dfs.name.dir</name> <value>/E:/ProgramFiles/hadoop/2.7.5/workplace/name</value> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>` |
c) 编辑etc\hadoop\mapred-site.xml
1 | `<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>hdfs://localhost:9001</value> </property> </configuration>` |
d) 编辑etc\hadoop\hdfs-site.xml
1 | `<configuration> <!-- 这个参数设置为1,因为是单机版hadoop --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.data.dir</name> <value>/E:/ProgramFiles/hadoop/workplace/2.7.5/data</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/E:/ProgramFiles/hadoop/2.7.5/workplace/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/E:/ProgramFiles/hadoop/2.7.5/workplace/data</value> </property> </configuration>` |
e) 编辑etc\hadoop\yarn-site.xml
1 | `<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>` |
f) 编辑etc\hadoop\hadoop-env.cmd,将set JAVA_HOME=%JAVA_HOME%中的%JAVA_HOME%替换为JDK的安装路径。
g) Windows的特殊配置
E:\ProgramFiles\hadoop\2.7.5\bin\winutils.exe chmod 777 /tmp/hive
必须以绝对路径运行winutils.exe,否测会报/tmp/hive没有写入权限的错。
4) 运行环境
a) 运行cmd窗口,执行“hdfs namenode -format”;
b) 运行cmd窗口,切换到hadoop的sbin目录,执行“start-all.cmd”,它将会启动4个进程。
5) 其他
a) 资源管理GUI:http://localhost:8088/
b) 节点管理GUI:http://localhost:50070/
3.4.Spark
1) 下载
2) 环境变量
新建环境变量SPARK_HOME,值:E:\ProgramFiles\spark-2.2.0-bin-hadoop2.7,并将E:\ProgramFiles\spark-2.2.0-bin-hadoop2.7\bin(或者%SPARK_HOME%\bin)放到Path中去。
3) PySpark
将将安装目录下的python\pyspark文件件拷贝到Python安装路径下的Lib\site-packages文件夹中,以文本为例对应的路径为C:\Python\Python34\Lib\site-packages。或者使用pip install pyspark进行安装(第一次使用pip命令会提示升级)(本文不建议这样安装pyspark包,因为出现一些问题,本文使用pip安装后,在IDE中使用时报错“int不是迭代对象”)。
4) 其他
对于日志信息的输出,则可以更改conf\log4j.properties文件(或者conf\log4j.properties.template拷贝一个副本,并重命名为log4j.properties),将里面的log4j.rootCategory=INFO, console更改为log4j.rootCategory=WARN, console或者log4j.rootCategory=ERROR, console,以便降低日志级别,使之只显示警告及更要的信息(WARN)或者是只显示错误信息(ERROR)。
参考:
https://blog.csdn.net/u011513853/article/details/52865076
https://blog.csdn.net/sinat_34070003/article/details/79676993
https://blog.csdn.net/lanchunhui/article/details/78848726
《Spark快速大数据分析》